
July 17, 2019 By: Mitra Mishra
Deep Learning, a buzzword today, has become the mainstay of the new age Artificial Intelligence applications. Since every business wants to scale up their AI competency, one thing is crucial to realize that the technology they choose to work with must be paired with an adequate deep learning framework, since each framework has a different purpose. Therefore, finding the perfect fit is necessary for smooth business growth as well as successful application deployment.
Most of the existing Deep Learning frameworks are Open-source. They are heavily invested by the tech giants like Google, Amazon, Facebook, Microsoft, Intel, IBM, Baidu and so on. Due to heavily invested by these companies there are dozens of deep learning libraries or tools available as open sources, but we will look at some of the most widely used frameworks.
TensorFlow
TensorFlow is an open-source library for numerical computation using the dataflow graph. The dataflow graph contains two parts first graph node which is used for mathematical operations while the edge represents the multidimensional array (Tensor) that flows between them. TensorFlow uses tensorboard for data visualizations and TensorFlow serving for rapid development of new algorithms while retaining the same server architecture and API.
TensorFlow is developed by the researchers and engineers from the Google brain team to conduct machine learning and deep neural network research.
Reason to use TensorFlow:
- End-to-End Solution: TensorFlow is an end-to-end open-source platform for machine learning and deep learning.
- Rich Open Source Community: TensorFlow has large open-source community support either from GitHub, Stack Overflow, Twitter, Quora or other different channels everywhere TensorFlow wins the race over its counterparts.
- Model Building: TensorFlow offers easy model building using the high-level API like Keras. It makes easy model iterations and easy debugging.
- Flexible Architecture: TensorFlow designed for large-scale distributed training and inference, but it is also flexible enough to support experimentation with new machine learning models and system-level optimizations.
- Language Support: TensorFlow provides stable API only in Python and C, but apart from it TensorFlow has also supports JavaScript, Java, C++, Go, Swift and R.
- Robust ML Production: TensorFlow offers easily train and deploy models in the cloud, on-prem, in the browser, or on-device no matter what language you use.
- Industries Adoption: There is no doubt TensorFlow is the best deep learning in present time, therefore, it has been adopted by several giants like Airbnb, Google, GE, Coca-Cola, Intel, Twitter, Bloomberg, Dropbox, Nvidia, Qualcomm, SAP, Uber, LinkedIn, etc. for solving their data-driven problems.
- Device Support: TensorFlow supports different devices and platforms like Mobile, Desktop, IoT devices, and web apps.
Pytorch
Pytorch is an open-source deep-learning library for python, based on torch machine learning libraries. Pytorch can construct complex deep neural networks and execute tensor computations. Pytorch offers a dynamic computation graph which is a reason to process variable-length input and output. Pytorch quickly became a favorite of researchers because it makes architecture building a cakewalk.
Pytorch is developed by Facebook, and it is used by Salesforce, Twitter, the University of Oxford and many others.
Some advantages of Pytorch:
- Architectures: The modeling process became straightforward and transparent due to its architectural style.
- Dynamic Computation Graph: Pytorch operates on a tensor and views any model as a direct acyclic graph. Unlikely to TensorFlow in Pytorch we can execute and change node as we go, we don’t need to define session interface and placeholder.
- Debugging: In the Pytorch computation graph defined on run time, therefore, we can use different python debugging tools like PDB, ipdb, etc.
- Visualizations: Pytorch uses Visdom for graphical representations. It is very convenient to use, and integration with tensorboard also does exist.
- Deployment: For deploying the model in Pytorch we need Flask or another alternative to develop a REST API on top of the model.
- Data Parallelism: The main feature of Pytorch is declarative data parallelism. Data parallelism is when we split the mini-batch of sample into multiple smaller mini-batches and run the computations for each of the smaller mini-batches in parallel. This is the way we can multiple GPU in parallel.
Keras
Keras is popular amongst deep learning enthusiasts and beginners. Keras is a python-based library that is run on top of TensorFlow, Theano or CNTK. It is also supported by Google.
Features of Keras:
- Fast and Easy: Prototyping is Keras is fast and easy.
- Support Multiple GPU: It supports multiple GPU like NVIDIA GPU, Google TPU.
- Supports both convolutional networks and recurrent networks, as well as combinations of the two.
MXNet
Apache MXNet (pronounced as mixnet) is a deep learning framework designed for efficiency and flexibility. It allows mixing symbolic and imperative programming to maximize efficiency and productivity. MXNet is portable and lightweight, scaling effectively to multiple GPU and machines.
Features of MXNet:
- It is quite fast and flexible.
- It supports an advanced GPU system.
- It offers easy model serving.
- It provides the support of many programming languages include Python, R, C++, Java, JavaScript.
- It can also run on any device.
- Data Parallelism and model parallelism: By default, MXNet uses data parallelism to partition the workload on multiple devices. It also supports model parallelism; in this approach, the model holds onto only part of the model.
- Gluon API: Gluon library in Apache MXNet provides a clear, concise, and simple API for deep learning. It makes it easy to prototype, build, and train deep learning models without sacrificing training speed.
- Dynamic Graph: Gluon enables developers to define neural network models that are dynamic, meaning they can be built on the fly, with any structure, and using any of Python’s native control flow.
Deeplearning4j
DeepLearning4j is the acronym as Deep learning for Jave is an open-source distributed deep learning library for JVM. Deep learning for java advantages of the latest distributed computing frameworks including Apache Spark and Hadoop to accelerate training on multiple GPU.
Deep learning for Java is written in Java and is compatible with any JVM language such as Scala, Closure or Kotlin. The underlying computations are written in C, C++ and Cuda. Kears will serve as Python API.
Deep learning for Java is widely adopted in industries as a distributed deep learning platform. Deeplearning4j can work comfortably with existing java ecosystems. Deeplearning4j can administrate on top of Hadoop and Spark.
Deepleaning4J is a great framework of choice with a lot of potential areas in image recognition, fraud detection and text mining, etc.
Features of Deeplearning4j:
- Fast and Efficient: Deeplearning4J is very robust and flexible it can process huge amounts of data without losing its speed.
- Distributed Deep Learning: It works with Apache Hadoop and Spark, on top of distributed CPU or GPU. Deeplearning4j also supports distributed architecture with multithreading.
- Commercially Accepted: Due to java centric, it is widely accepted by industries for their AI implementations because most of the companies using Java in their applications.
- Devices Support: Deeplearning4J is cross-platform it can be used in Windows, Linux, Mac and Mobile devices also.
- Open Source: The Deeplearning4j is pure open-source, Apache 2.0 and maintained by the developer community and Skymind.
Microsoft CNTK
Microsoft cognitive toolkit is an open-source deep-learning library released and maintained by Microsoft. CNTK describes a neural network as a series of computational steps via a directed graph. It allows easy combinations of different model types such as feed-forward DNNs, convolutional nets (CNNs), and recurrent networks (RNNs/LSTMs). It implements stochastic gradient descent (SGD, error backpropagation) learning with automatic differentiation and parallelization across multiple GPUs and servers.
Features of Microsoft CNTK:
- Speed and Scalability: The Microsoft Cognitive Toolkit trains and evaluates deep learning algorithms faster than other available toolkits, scaling efficiently in a range of environments—from a CPU to GPUs, to multiple machines—while maintaining accuracy.
- Commercial Grade Quality: It is built with a sophisticated algorithm and production reader to work on massive datasets. Skype, Bing, Cortana and other industries already using CNTK to develop commercial-grade AI.
- Efficient Resource Usages: It allows Parallelism with accuracy on multiple GPU machines.
- Open Source: Since this is an open-source project initiated by Microsoft therefore community can take advantage through exchanging of open-source working codes.
Conclusion
So far, we have seen different deep learning platforms and we found all deep learning libraries serve best according to their purposes, but we need to find out what types of work we are going to perform with the help of deep learning. Here:
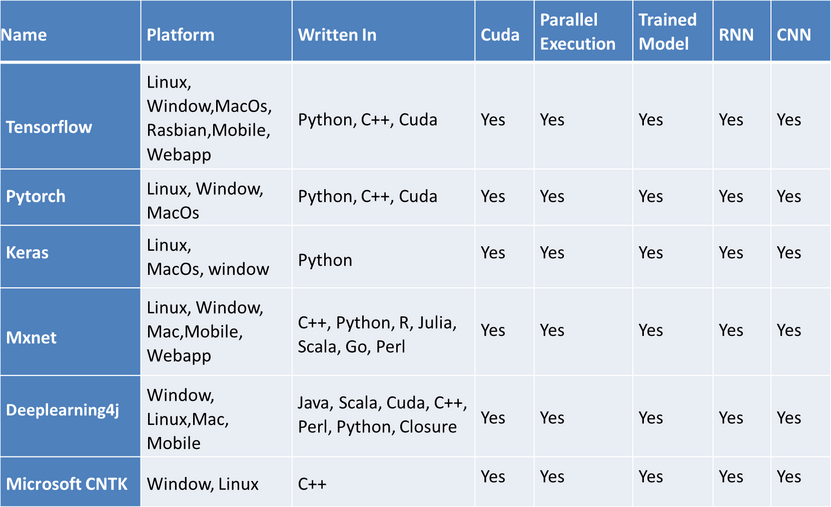
As we saw in the table every platform has some specifications. Everyone can start with any of the deep learning libraries but should be aware of the use cases like suppose someone wants to do some research type of things then Pytorch is very perfect for him instead of others (I am not saying that TensorFlow is not good for this purpose). Therefore, we should consider several factors while choosing a perfect framework for a deep learning project.
There are some given factors below:
- The programming language you want to use in your project.
- The Budget you have.
- Type of neural network you want to develop.
- Objective and purpose of the projects.
